Research
These are the research areas that I work on currently. My PhD thesis is about applying Data Mining techniques on Software Engineering data. For more information about it, click here. The findings of the thesis have also laid the groundwork for writing a book, titled “Mining Software Engineering Data for Software Reuse”. More information about the book can be found here. For my past research work click here.
Mining Software Repositories
Nowadays, software development has been greatly influenced by the vastness of available online resources, including source code indexes (e.g. GitHub), question-answering communities (e.g. Stack Overflow), source code search engines, etc. A new problem-solving paradigm has emerged; developers search online for solutions to their problems and integrate them, thus greatly reducing development time and most of the time even improving the overall quality of the software product. Interesting lines of work in this area involve analyzing the problem of locating useful solutions and/or reusable software components from a functionality and from a reusability perspective.

A typical example of locating useful information is that of searching in a question-answering community. In this context, the challenge for developers usually lies in effectively navigating between question posts until they find a similar question that has already been answered. A proposed improvement on current question-answering systems involves using the main elements of a question post, including not only its title, tags, and body, but also its source code snippets. This is the subject of our latest work, which involves designing a similarity scheme for the title, tags, body, and source code snippets of question posts in Stack Overflow and illustrating how the extracted information can be used to further improve the retrieval of questions. Using this methodology, similar question posts can be recommended more effectively while community members can search for solutions even without fully forming a question.
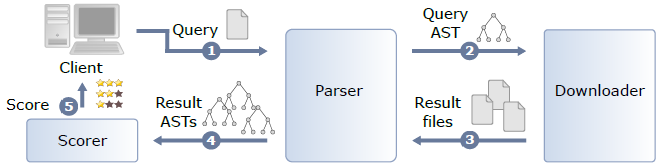
In accordance with the typical scenario of finding reusable software components and integrating them to one's source code as outline above, several systems have already been developed. These systems lie in the area of Recommendation Systems in Software Engineering (RSSEs). Most RSSEs focus on covering the functionality desired by the developer, while possibly neglecting the quality of the recommended code. As an improvement we have proposed an RSSE that employs functional and non-functional component selection criteria in order to provide not only a functional ranking for the retrieved components, but also a reusability score for each component based on configurable thresholds of source code metrics.
Software Quality
Software Quality is a rather broad concept, as it means different things to different people. In the context of software development, source code analysis may be distinguished into static analysis and dynamic analysis. Static analysis involves analyzing the source code of a software project or generally component, whereas dynamic analysis operates on the executable (bytecode) of the component, usually by analyzing execution traces. Certain lines of work in this area focus on improving existing software quality and on localizing or predicting bugs in a software system, either by using the aforementioned source code metrics or by using metrics from version control systems.
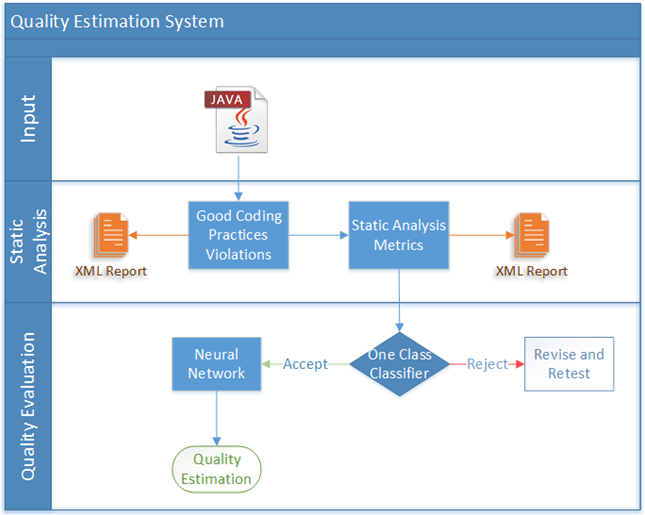
Concerning static analysis, there are several tools that aspire to assess the quality of source code using source code metrics such as e.g. Number of Lines of Code, McCabe Computational Complexity etc. These tools usually include a model with thresholds for these metrics which has to be defined by some experts. Our work in this area (performed with Michail Papamichail and Andreas Symeonidis) involves constructing a generic methodology that relates quality with source code metrics while alleviating the need for expert help by using software component popularity as ground truth. Using the methodology, developers are able to evaluate the quality of components found in online sources before integrating them in their source code. The system initially rules out any low quality code using a one-class classifier, and subsequently computes a quality score for each software component by means of a neural network trained on high quality code. Further work on this area has resulted in the development of an extended mechanism that effectively determines the correlation of the metrics with respect to source code quality. The output of the mechanism is a comprehensive analysis on five source code quality axes: complexity, coupling, documentation, inheritance, and size.
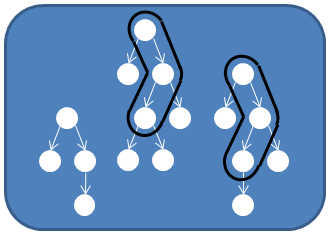
Another quite interesting research area of software quality is that of dynamic bug localization. The main concept of this area involves determining the location of non-crashing software bugs using dynamic analysis, i.e. parsing function call traces. An example methodology involves instrumenting the source code of an application, collecting function call traces and representing them as graphs. After that, these graphs are mined using subgraph mining algorithms in order to detect interesting patterns, i.e. patterns occuring mostly on erroneous executions, and thus provide a ranking of potentially buggy functions-nodes. An interesting extension to existing work is the application of tree edit distance algorithms in order to reduce the graph dataset and improve the scalability and effectiveness of state-of-the-art methods. Further exploring the task of selecting the most significant patterns, we also propose a set of different call trace selection techniques based on the Stable Marriage problem to localize possibly buggy areas more effectively.
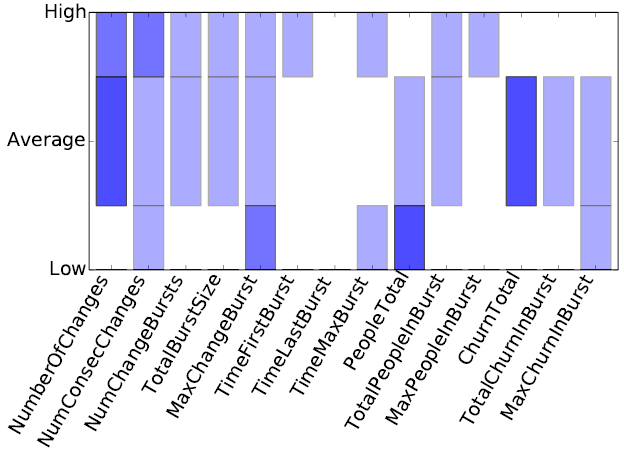
Focusing on metrics derived from version control systems, the problem, which can also be defined as Software Reliability Prediction, has attracted the attention of several researchers and thus several classification techniques have been developed in order to classify software components as defect-prone or defect-free. Further advancing current research, our work in this area involves designing a genetic fuzzy rule-based system so as to produce interpretable output concerning software reliability. In specific, the system uses a Mamdani-Assilian inference engine and the problem is modeled as a one-class classification task (where the class that is predicted is the defect-proneness of software classes). The genetic algorithm follows the Pittsburgh approach where each chromosome represents a rule base.
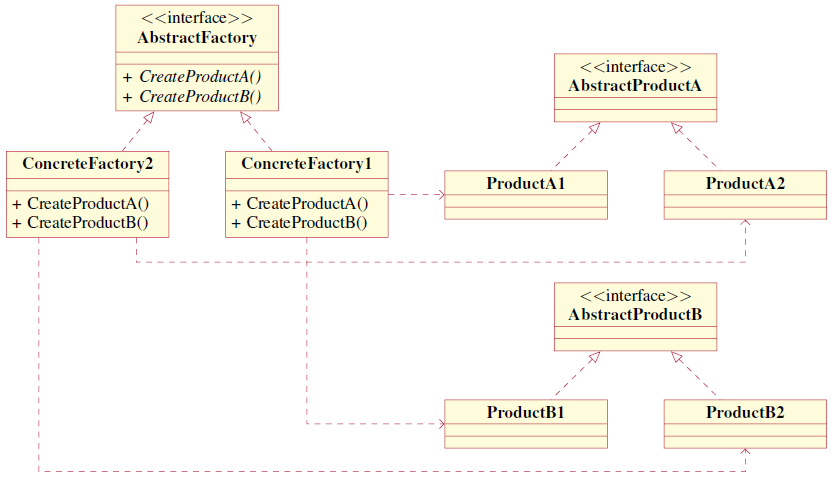
Apart from quality measured by source code metrics and bug detection, an interesting line of research involves determining whether a software project follows certain design patterns. Design patters are typically employed to cover the non-functional aspects of the system and thus identifying them is important for understanding and subsequently reusing or maintaining a software project. This is a task performed by Design Pattern Detection (DPD) tools, which may operate on the source code or on some other representation of the information. Our work in this area (performed with Antonis Noutsos and Andreas Symeonidis) resulted in a design pattern detection tool with a descriptive representation that recovers design patterns from source code. Compared to other DPD tools that identify known patterns, our tool also detects custom patterns while it also allows identifying exact and approximate pattern variations even in non-compilable code.
Software Requirements
The translation of requirements to specifications and subsequently source code is one of the most challenging tasks of the software development process. In specific, requirements are usually provided in multimodal formats, including e.g. natural language text, graphical storyboards, etc., hence mapping them to specifications requires designing the appropriate representations. Furthermore, since functional requirements are commonly written in natural language, they are prone to ambiguity, incompleteness and inconsistency.
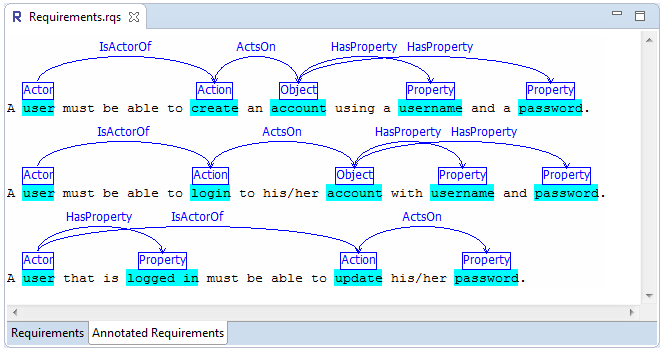
As a result, there are several approaches that constrain the input format of requirements, use controlled languages and/or require considerable human effort in order to translate them to specifications. An interesting idea is the automation of the process of converting natural language input to formal semantic representations using semantic parsers. Our latest work in this area involved formally defining the problem, designing an hierarchical annotation framework and a requirements ontology to allow intuitively marking and storing requirements concepts. After that, requirements concepts are identified using semantic role labeling techniques and finally these concepts are stored in the ontology to allow further processing.
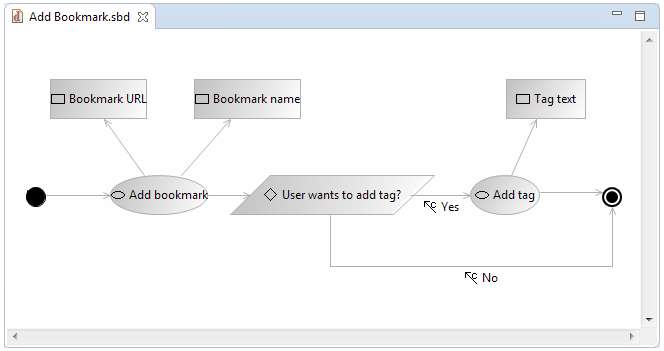
Another issue when converting requirements to specifications is the integration of requirements from different sources having also possibly different formats. These specifications can then later be used to provide the model of the application or even generate its source code using Model-Driven Engineering (MDE). In this context, we have developed a methodology that allows developers to design their envisioned system through software requirements in multimodal formats. Our methodology employs natural language processing techniques and semantics in order to process textual requirements and graphical storyboards and integrate them into specifications. The procedure is also traceable, as any changes in software requirements are propagated to the produces software models.